
Queue
A queue is a kind of linear data structure used to process components in a fair and orderly manner. The basic principle of a queue is to guarantee that the first element added is the first to be processed or removed. It can be thought of as a collection of elements where new elements are added at one end, usually referred to as the "rear," and existing elements are removed from the other end, known as the "front." In situations where upholding order is essential, this conduct is invaluable.
One well-known characteristic of queues is the application of the "First-In-First-Out" (FIFO) rule. This article will introduce the idea of queues, discuss their fundamental functions, various implementations, and practical uses, emphasizing their relevance in a variety of fields.
Because of their extraordinary adaptability, queues are used in many contexts where maintaining balance and fairness is crucial. They are essential for handling service requests, scheduling procedures, and managing network packets, among many other applications that call for an organized and methodical approach.
Operations on Queues: Enqueue, Dequeue, Peek
Three basic operations are the basis of a queue's functionality:
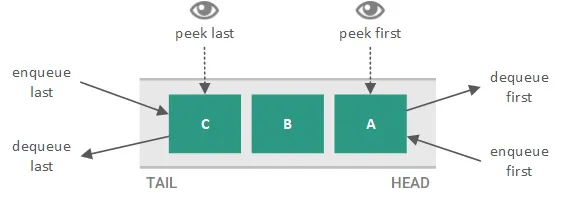
Enqueue: Adding an element to the back of the queue is the enqueue action. Placing itself at the end of the line, the newly inserted element waits to be processed.
Dequeue: In contrast, the dequeue operation removes the element from the front of the queue. This signifies that the element at the front has been successfully processed, and the next element in line steps up to become the new front.
Peek: One characteristic that sets queues apart is the peek procedure. You can examine the element at the head of the queue without taking it out thanks to this feature. This is incredibly helpful when conducting checks.
Array-based Queue Implementation: In an array-based queue, elements are stored in an array. Two vital indices, often referred to as "front" and "rear," manage the positions of the front and rear elements in the queue. The front index points to the front element, while the rear index points to the rear element. As elements are enqueued, the rear index is adjusted, and when elements are dequeued, the front index is updated. This method is straightforward and efficient for most use cases.
Linked List-based Queue Implementation: In a linked list-based queue, a linked list is employed to store the elements. The front of the queue corresponds to the head of the linked list, while the rear of the queue is represented by the tail of the linked list. As elements are enqueued, they are added to the tail of the linked list, and when elements are dequeued, they are removed from the head of the linked list. Linked list-based queues offer flexibility and efficiency, especially in situations where the size of the queue may vary dynamically.
Circular Queues and Priority Queues
In addition to the traditional queue structure, we encounter two noteworthy variations: circular queues and priority queues.
Circular Queues: A circular queue is an adapted version of a standard queue. In a circular queue, when the rear end of the queue reaches the limit of the underlying data structure (typically an array), it seamlessly loops back to the front. This circular behavior optimizes the utilization of available space within the underlying array. Circular queues prove particularly valuable in scenarios where maintaining a fixed queue size or circular operation is essential, as seen in specific scheduling or buffering scenarios.
Priority Queues: Priority queues constitute a specialized form of a queue where each element is attributed a priority value. Elements possessing higher priorities are dequeued and processed ahead of those with lower priorities. Priority queues can be constructed using various data structures, including heaps or balanced binary search trees. They find application in situations where the prioritization of elements is of utmost importance, such as scheduling within operating systems, the management of network traffic through algorithms, and other contexts where the processing order hinges on the relative importance of the elements.
Applications and Use Cases of Queues
Queues have a wide array of applications across diverse domains. Here are some common use cases:
Job Scheduling: Queues are widely used for scheduling tasks, jobs, or processes in operating systems, job queues, and task management systems. They ensure that tasks are processed in an orderly manner, promoting fairness and efficiency.
Buffering: In networking protocols, queues are employed to buffer incoming requests, messages, or packets. This buffering mechanism guarantees that data is processed sequentially, preventing data loss or out-of-order processing.
Breadth-First Search (BFS): BFS is a graph traversal algorithm that uses queues to visit neighboring nodes in a breadth-first manner. By systematically exploring the graph's nodes, BFS is a crucial algorithm for various applications, including social network analysis, web crawling, and pathfinding.
Simulations: Queues are employed to simulate real-world scenarios, such as waiting lines at a bank, traffic signals, or event handling systems. By using queues, these simulations can replicate the behavior of processes or entities waiting for their turn in a structured and orderly fashion.
Print Spooling: Printers make use of queues to manage print jobs. Print spooling ensures that print jobs are processed in the order they are received, avoiding conflicts and ensuring efficient printing operations.
Conclusion
In conclusion, queues are a versatile and indispensable data structure. They provide a mechanism for maintaining order, fairness, and efficient data processing, making them a fundamental concept in various practical applications. Whether you're exploring algorithms, network protocols, or scheduling systems, understanding queues is key to designing efficient and orderly data processing systems.
Posted using Honouree