
Researchers have developed a technology that allows a filmed speech to be modified simply by editing the text of the verbal transcription. Fake news enthusiasts will love it.

Automatically editing a video interview has never been easier. Researchers at Princeton and Stanford Universities and the Max Planck Institute have just published a technique that allows the content of a video speech to be modified simply by editing the text of the verbal transcript.
The system is then able, from the new text, to create the corresponding video interview, without interruptions or jolts, as if it were original. This allows you to add and delete words, or simply rearrange them. The result is so amazing that most people who watch these modified videos think they are true.
Examples are shown in a presentation video on YouTube.
Other researchers are also exploring this field of automatic video generation. In 2017, a group from the University of Washington had succeeded in creating an artificial video of Barack Obama from an existing audio track.
In comparison, the technique just presented by the Princeton and Stanford researchers is superior, because it avoids the need to make an audio recording: all you have to do is edit a text.
How is this modification work carried out?
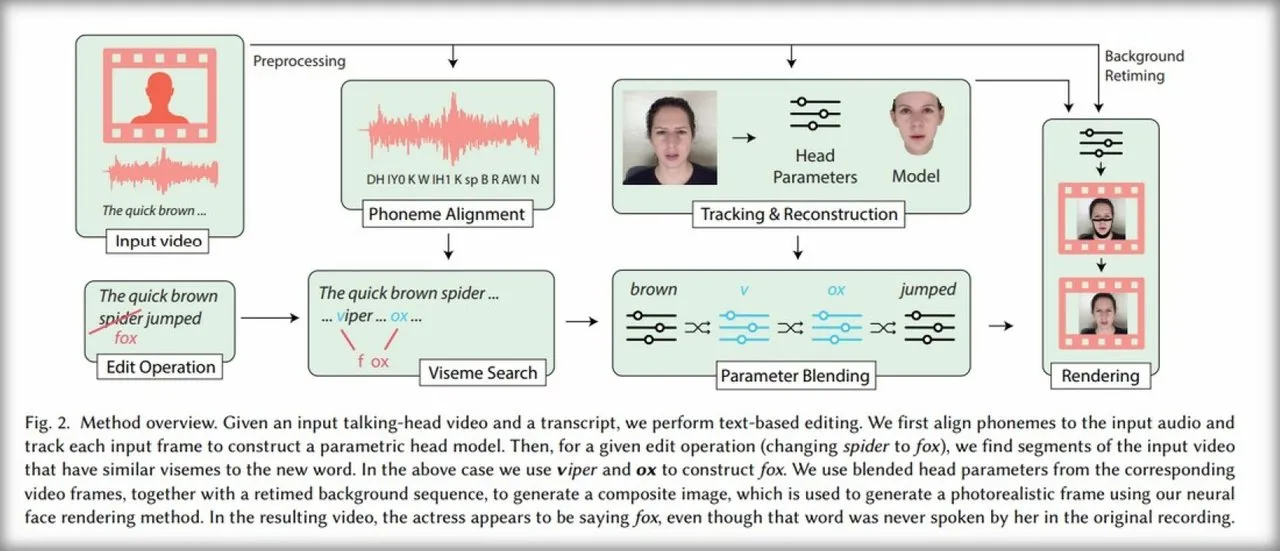
The system created by the researchers will first analyze the video and verbal transcription to recognize not only phonemes but also "vises". That is, the elementary facial expressions associated with phonemes. The system will then analyze the changes made to the text and identify the visions that should be used to modify the video.
A 3D modeling, then a neural network
The new sequences are then created in two steps. First, the software will generate a 3D model of the movements of the mouth and jaw, while respecting the general conditions of the video: exposure, lighting, head position, etc. In a second step, a previously trained neural network will transform these 3D models into realistic video sequences.
For the audio part, researchers use different methods: either they re-record the new text with the original person, or they artificially generate the new audio parts with software such as Adobe VoCo.
Obviously, researchers do not want their technology to be used to maliciously manipulate speeches or interviews. They see it as an additional tool in audio-video production processes, for example, to correct recording errors. The software could also be used to generate realistic video sequences for a virtual assistant.
In all cases, the use of this technology should be open and transparent, and with the consent of the person being filmed. To avoid fraudulent and malicious creations, researchers believe that more verification techniques, such as forensic analysis or watermarking, should be developed.

Sources: Stanford's Project and YouTube

I've made a lot of articles with tools, explanations and advises to show you how to protect your privacy and to secure your computer, GO check them out!
This is my guide To Secure your PC after a fresh installation of Windows
If you think that your Phone or your PC has been hacked, you have to check it right now!
That's how you can be more Anonymous on the internet!
The Future of Cyber-Security, what to expect?
The best Crypto debit card – Wirex!
These are the best VPN to protect your numeric life: NordVPN, ExpressVPN and CyberGhost!
Your PC is slow? That's why!
Why is it important to Be Discreet on the Internet
Feel hot? Your Computer also!
How an Adware works?
That's how you should guard against Trojan!
What are the different Types of hackers?
