
Learn Python Series (#13) - Mini Project - Developing a Web Crawler Part 1

What Will I Learn?
You will learn how to install and import the Requests and BeautifulSoup4 libraries, so we can fetch and parse web page data,
- a brief look (again) about how HTML and CSS work,
- in order to use that knowledge to select specific HTML elements with the bs4
select()method, - how to "think ahead" about coding your custom custom web crawler,
- about where to look inside html code structure to find and fetch the exact data you are interested in, - how to finetune your parsed data,
- and to wrap it all in a re-usable function.
Requirements
- A working modern computer running macOS, Windows or Ubuntu
- An installed Python 3(.6) distribution, such as (for example) the Anaconda Distribution
- The ambition to learn Python programming
Difficulty
Intermediate
Curriculum (of the Learn Python Series):
- Learn Python Series - Intro
- Learn Python Series (#2) - Handling Strings Part 1
- Learn Python Series (#3) - Handling Strings Part 2
- Learn Python Series (#4) - Round-Up #1
- Learn Python Series (#5) - Handling Lists Part 1
- Learn Python Series (#6) - Handling Lists Part 2
- Learn Python Series (#7) - Handling Dictionaries
- Learn Python Series (#8) - Handling Tuples
- Learn Python Series (#9) - Using Import
- Learn Python Series (#10) - Matplotlib Part 1
- Learn Python Series (#11) - NumPy Part 1
- Learn Python Series (#12) - Handling Files
Learn Python Series (#13) - Mini Project - Developing a Web Crawler Part 1
In the previous Learn Python Series episodes, we learned about handling different Python data types (such as strings, lists, dictionaries, tuples), about defining self-built functions returning values, plotting some data, and in the previous episode we learned how to read from and write to files.
But up until now, we have only been using dummy data because we were tied to using the dtaa on our own computer. That's going to change in this episode, which will be the kick-off of something new for the Learn Python Series, a Mini Project, consisting of multiple parts, in which we'll:
- learn new things, such as how to fetch data from the web using the
requestsmodule, - and how to parse HTML in a DOM-like fashion, using the
beautifulsoup4module, - discuss a few core mechanisms on how to build a custom web crawler based on specific rules on what you're looking for,
- and build (some components of) such a web crawler as well.
But first things first: let's learn how to connect to the web and fetch some data from a URL.
Using the Requests HTTP library
In order to connect to the web and fetch data from a URL, many options are available. Today I'll introduce you to the Requests HTTP library (developed by the well-known Pythonista Kenneth Reitz).
If you haven't already, you can simply install Requests via the command line with:
pip install requests
Next, create a new oroject folder, call it webcrawler/, cd into it, add a file webcrawler.py to it, and open that file with your favorite code editor. Begin with importing requests like so:
import requests
The get() method
We are now able to use requests in our web crawler code. Now let's try to get ("fetch") my Steemit acocunt page from the web! We'll first define a url (my account page on Steemit.com), and then we'll use the requests get() method, pass in that url, and if all goes well as a result we'll get a so-called Response object returned.
Like so:
url = 'https://steemit.com/@scipio'
r = requests.get(url)
print(r)
<Response [200]>
The text attribute
All did go well, in this case, becase the Response object returned 200, which is a status code telling us "OK! The request has succeeded!". That's all good and well, but where is the web content from my account page? How do we get that returned?
When making a web request, Requests tries to "guess" the response encoding (which we could change if we like) but since we're clearly dealing with (mostly) HTML (and some JS) content on my account page, let's call the text attribute the Requests library provides and print its response, like so:
url = 'https://steemit.com/@scipio'
r = requests.get(url)
content = r.text
print(content)
The printed result contains all of my account page source code, which begins with this (it's too much to print completely for this tutorial, this is just to give you an idea of the content string value:
<!DOCTYPE html><html lang="en" data-reactroot="" data-reactid="1" data-react-checksum="733165241"><head data-reactid="2"><meta charset="utf-8" data-reactid="3"/><meta name="viewport" content="width=device-width, initial-scale=1.0" data-reactid="4"/><meta name="description" content="The latest posts from scipio. Follow me at @scipio. Does it matter who's right, or who's left?" data-reactid="5"/><meta name="twitter:card" content="summary" data-reactid="6"/><meta name="twitter:site" content="@steemit" data-reactid="7"/><meta name="twitter:title" content="@scipio" data-reactid="8"/><meta name="twitter:description" content="The latest posts from scipio. Follow me at @scipio. Does it matter who's right, or who's left?" data-reactid="9"/>
More response object attributes
The response object contains many attributes we could use to base decisions upon. Which ones are provided? Let's run:
dir(r)
['__attrs__',
'__bool__',
'__class__',
'__delattr__',
'__dict__',
'__dir__',
'__doc__',
'__enter__',
'__eq__',
'__exit__',
'__format__',
'__ge__',
'__getattribute__',
'__getstate__',
'__gt__',
'__hash__',
'__init__',
'__init_subclass__',
'__iter__',
'__le__',
'__lt__',
'__module__',
'__ne__',
'__new__',
'__nonzero__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__setattr__',
'__setstate__',
'__sizeof__',
'__str__',
'__subclasshook__',
'__weakref__',
'_content',
'_content_consumed',
'_next',
'apparent_encoding',
'close',
'connection',
'content',
'cookies',
'elapsed',
'encoding',
'headers',
'history',
'is_permanent_redirect',
'is_redirect',
'iter_content',
'iter_lines',
'json',
'links',
'next',
'ok',
'raise_for_status',
'raw',
'reason',
'request',
'status_code',
'text',
'url']
For example, if we want to print the response status code, we run:
print(r.status_code)
200
To view the response encoding:
print(r.encoding)
utf-8
To know if the respone contains a well-formed HTTP redirect, or not:
print(r.is_redirect)
False
A brief intro about HTML and CSS
If you haven't read my Wordpress tutorial series, in which I explained HTML and CSS structures, here's a brief overview regarding just that. You need this info to be able to work with the Beautifulsoup4 library (discussed below):
- HTML, short for Hyper Text Markup Language, is the de facto language to structure web pages and add content to is;
- CSS, short for Cascading Style Sheets, is the de facto language to stylize web pages,
- the HTML language consists of tags, most of the time opening and closing tags in which either content or another nested tag is placed,
- HTML tags consist of elements, attributes and values. For example on a hyperlink, the
<a>element is used, the hyperlink url is contained as a value inside the attributehref. For example:
<a href="https://www.google.com/">Google</a>
- HTML tags may contain one or more class attributes and/or id attributes. For example:
<div class="wrapper"></div> or <section id="content"></section>
- If we nest the above examples, a nested sub-structure like this is formed:
<section id="content">
<div class="wrapper">
<a href="https://www.google.com/">Google</a>
</div>
</section>
- In CSS, every statement consists of a selector which is used to select certain HTML elementsto a apply a certain styling to. After the selector a set of curly braces
{}is placed, in which pairs of property and property values are put. For example:
a { color: red; text-decoration: none; }
In the example above, all
<a>HTML elements are selected, meaning all hyperlinks will be displayed with a red font color and without an underline (no text decoration).If we want to select an element with a specific id attribute, we append the
#sign to the element (used to target a specific id) followed by the id value, like so:
section#content { background-color: #eee; }
- If we want to select one or more elements with a specific class attribute, we append the
.sign to the element (used to target a specific id) followed by the id value, like so:
div.wrapper { width: 960px; }
- In case we want to target specific elements that don't have a class or id name (which is the case with the
<a>tag in the above example) we can use the following notations:
section#content a { color: green; }
... which means all descendants of section#content having the element a, so, this notation doesn't require a to be a direct child of section#content ! The a element may be nested multiple nested layers deep.
or for example:
div.wrapper > a { color: green; }
... which means only direct a children contained directly inside all <div>s with class="wrapper".
We are able to use these type of selector notations using the Beautifulsoup4 library, which we'll discuss (at least some of the basics of) hereafter.
Using the Beautifulsoup4 library
The response text output, stored inside the content variable I created, was all the HTML/JS source code that is on my own Steemit account page. To distill useful data from that wall of code, we need to parse the content string. Now we could Go Harcore and parse it all ourselves using the skills we learned in the Handling Strings episodes in the Learn Python Series, but it's far more convenient (and robust) to use the well-known Beautifulsoup4 library. It is a "jQuery selector engine-like" HTML parsing library and if you haven't already, first install it via:
pip install beautifulsoup4
... and then you're good to go!
Next import it like so:
from bs4 import BeautifulSoup
Next, let's create a BeautifulSoup object, call it soup, and pass in the content string we fetched from my account page using the text attribute after calling the requests.get() method. BS4 contains multiple parsers, let's use 'lxml':
soup = BeautifulSoup(content, 'lxml')
print(type(soup))
<class 'bs4.BeautifulSoup'>
bs4 object attributes and methods
Ok, our soup bs4 object holds all the information the content string has, but we can now also use various bs4 attributes and built-in methods to navigate over the soup data structure. For example:
The title attribute
To distill my account page's <title> tag:
page_title = soup.title
print(page_title)
<title data-reactid="36">Steemit</title>
Nota bene: If we use our regular web browser, visit https://steemit.com/@scipio then in the top browser tab where the title is displayed it shows scipio (@scipio) - Steemit, which as you can see is different than the result we got in out <title> tag: Steemit. That's because the steemit.com website uses a JavaScript framework called ReactJS, which renders a bunch of data and modifies the DOM at run-time, andit also downloads more content than it did initially if you for example scroll down on any Steemit page, where you then experience a "load time" before all new content is displayed. That DOM-rendering done by ReactJS is not contained inside the initially downloaded HTML and therefore bs4 can't render the data the same a reactJS does.
But that's just a minor detail and doesn't really matter for now. Let's continue with some more built-in bs4 attributes and methods.
The select() method
The bs4 library provides us with a very convenient select() method, in which you can pass in CSS / jQuery-like selectors to navigate your way through and distill various HTML components. These are the same type of notations we have discussed above regarding CSS selectors.
For example, if we want to fetch all <h1> elements on the page (2 in this example), we could run the following code, and please notice that 'h1' is passed as the select() argument:
h1 = soup.select('h1')
print(len(h1))
print(h1)
2
[<h1 data-reactid="150"><div class="Userpic" data-reactid="151" style="background-image:url(https://steemitimages.com/u/scipio/avatar);"></div><!-- react-text: 152 -->scipio<!-- /react-text --><!-- react-text: 153 --> <!-- /react-text --><span data-reactid="154" title="This is scipio's reputation score.
The reputation score is based on the history of votes received by the account, and is used to hide low quality content."><span class="UserProfile__rep" data-reactid="155"><!-- react-text: 156 -->(<!-- /react-text --><!-- react-text: 157 -->61<!-- /react-text --><!-- react-text: 158 -->)<!-- /react-text --></span></span></h1>, <h1 class="articles__h1" data-reactid="208">Blog</h1>]
The select() method returns a list, named h1 in this case, in which all selected bs4 element tags are contained:
h1 = soup.select('h1')
for h1_item in h1:
print(type(h1_item))
<class 'bs4.element.Tag'>
<class 'bs4.element.Tag'>
Knowing what to look for and where
Developing a custom web crawler means:
-1- having a plan what to look for,
-2- knowing where that exact data is located inside a web page,
-3- understanding how to first extract and later use (and/or store) that data.
HTML is a language that's able to structure web contents. But there are many ways a web developer could choose to structure that data, there are a lot of web developers, and even more websites on the entire world wide web. This means that just about every website uses a completely different HTML structure. And the content kept inside those web structures is even more different.
As a consequence, it's extremely difficult - almost impossible actually - to develop only one web crawler that you could just point to any web page to "auto-distill" and return the exact data you're looking for. It doesn't work that way, unfortunately. However, because most websites use "templates" - which are like "molds" from where pages are created, oftentimes similar pages are built using the same templates.
The technical structure of my account page (https://steemit.com/@scipio) is technically structured in the same way as any other Steemit account page. This means, that if we write a bs4 parsing procedure that correctly fetches and distills the data we want to use from my page, we can use the exact same code to distill similar data from all other Steemit account pages. That's something we can work with!
Test case: fetch the urls linking to my 20 latest article posts (including my resteems)
-1- Q: What are we looking for?
=> A: the urls linking to my 20 latest posts (including my resteems).
-2- Q: Where is that data located on the page?
=> A: open up your favorite browser, go to my web page (https://steemit.com/@scipio), open up the Browser Developer Console (Inspector), and point to / click on the top post link.
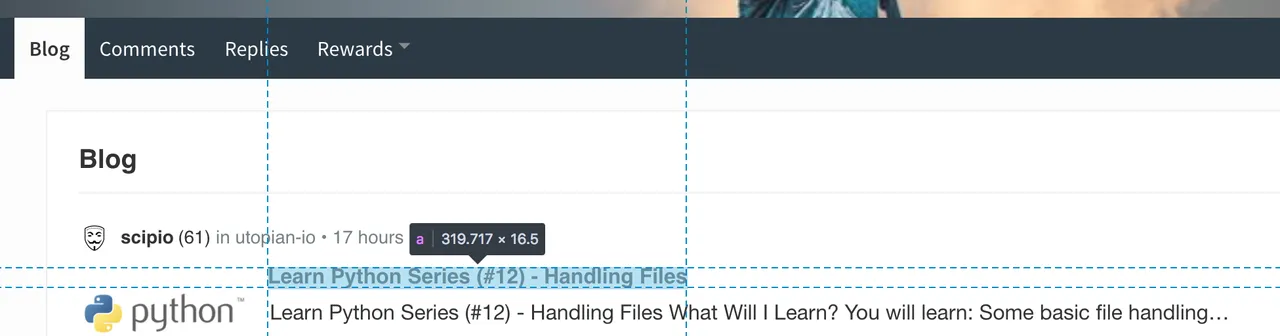
As you can see the <a> tag we are interested in, doesn't have a class attribute: that's a pity, because if those <a> tags we're interested in right now would have had a class attribute, we could have used that directly. However.... the <a> tag is a direct child of an <h2> element that does have a specific class name: articles__h2. We can use that instead!
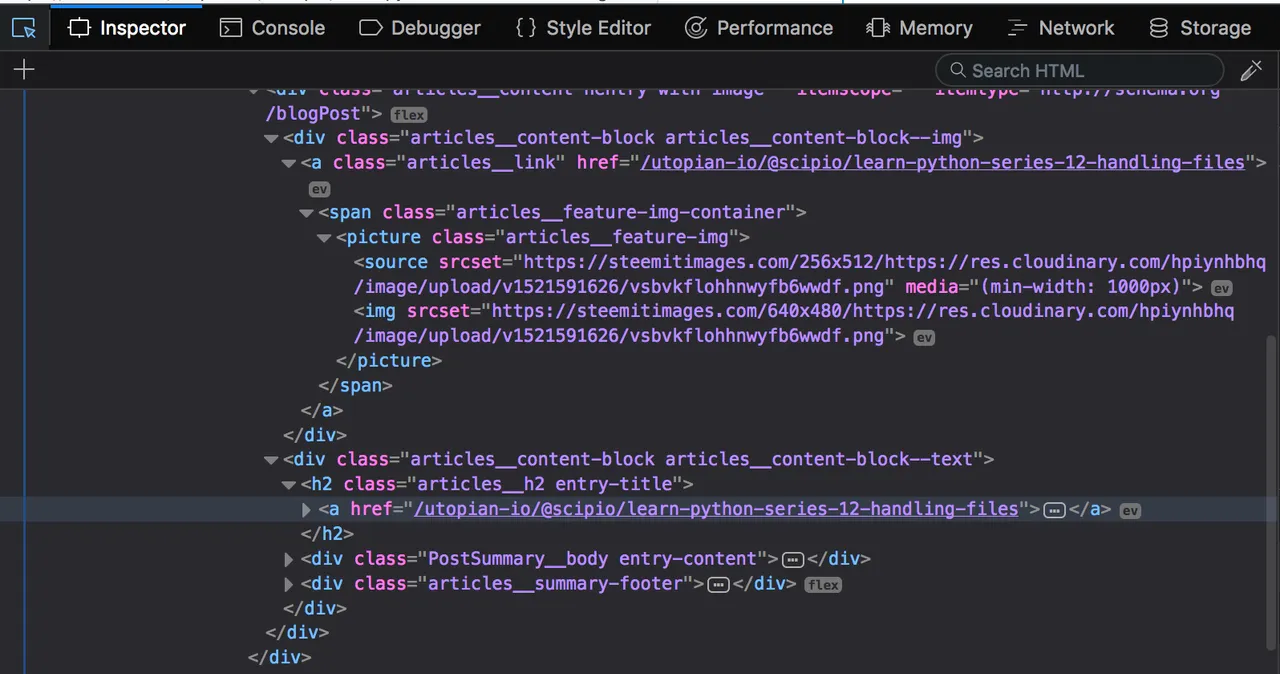
-3- Q: How to extract the data?
=> A: we must simply use the select() method again, but this time we pass in the appropriate selector containing all the <h2> class elements having the class name articles__h2 and fetch the <a> tag nested inside it. Like so:
anchors = soup.select('h2.articles__h2 a')
print(anchors)
[<a data-reactid="257" href="/utopian-io/@scipio/learn-python-series-12-handling-files"><!-- react-text: 258 -->Learn Python Series (#12) - Handling Files<!-- /react-text --></a>, <a data-reactid="337" href="/utopian-io/@scipio/learn-python-series-11-numpy-part-1"><!-- react-text: 338 -->Learn Python Series (#11) - NumPy Part 1<!-- /react-text --></a>, <a data-reactid="417" href="/utopian-io/@scipio/learn-python-series-10-matplotlib-part-1"><!-- react-text: 418 -->Learn Python Series (#10) - Matplotlib Part 1<!-- /react-text --></a>, <a data-reactid="497" href="/utopian-io/@scipio/learn-python-series-9-using-import"><!-- react-text: 498 -->Learn Python Series (#9) - Using Import<!-- /react-text --></a>, <a data-reactid="576" href="/utopian-io/@scipio/learn-python-series-8-handling-tuples"><!-- react-text: 577 -->Learn Python Series (#8) - Handling Tuples<!-- /react-text --></a>, <a data-reactid="655" href="/utopian-io/@scipio/learn-python-series-7-handling-dictionaries"><!-- react-text: 656 -->Learn Python Series (#7) - Handling Dictionaries<!-- /react-text --></a>, <a data-reactid="734" href="/utopian-io/@scipio/learn-python-series-6-handling-lists-part-2"><!-- react-text: 735 -->Learn Python Series (#6) - Handling Lists Part 2<!-- /react-text --></a>, <a data-reactid="813" href="/utopian-io/@scipio/learn-python-series-5-handling-lists-part-1"><!-- react-text: 814 -->Learn Python Series (#5) - Handling Lists Part 1<!-- /react-text --></a>, <a data-reactid="892" href="/utopian-io/@scipio/learn-python-series-4-round-up-1"><!-- react-text: 893 -->Learn Python Series (#4) - Round-Up #1<!-- /react-text --></a>, <a data-reactid="971" href="/utopian-io/@scipio/learn-python-series-3-handling-strings-part-2"><!-- react-text: 972 -->Learn Python Series (#3) - Handling Strings Part 2<!-- /react-text --></a>, <a data-reactid="1050" href="/utopian-io/@scipio/learn-python-series-2-handling-strings-part-1"><!-- react-text: 1051 -->Learn Python Series (#2) - Handling Strings Part 1<!-- /react-text --></a>, <a data-reactid="1129" href="/utopian-io/@scipio/learn-python-series-intro"><!-- react-text: 1130 -->Learn Python Series - Intro<!-- /react-text --></a>, <a data-reactid="1208" href="/steemit/@scipio/it-s-my-birthday-on-steemit-100-days"><!-- react-text: 1209 -->It's my Birthday, on Steemit! 100 .... Days! ;-)<!-- /react-text --></a>, <a data-reactid="1287" href="/steemdev/@scipio/i-m-still-here-ua-python-is-coming"><!-- react-text: 1288 -->I'm still here! :-) UA-Python is coming!<!-- /react-text --></a>, <a data-reactid="1365" href="/introduce-yourself/@femdev/let-s-introduce-myself-femdev"><!-- react-text: 1366 -->Let's introduce myself! Femdev!<!-- /react-text --></a>, <a data-reactid="1449" href="/utopian-io/@howo/introducing-steempress-beta-a-wordpress-plugin-for-steem"><!-- react-text: 1450 -->Introducing SteemPress beta, a wordpress plugin for steem<!-- /react-text --></a>, <a data-reactid="1533" href="/pixelart/@fabiyamada/a-little-present-for-scip-sensei-the-scipio-files-pixelart"><!-- react-text: 1534 -->A little present for scip sensei! The scipio files pixelart!<!-- /react-text --></a>, <a data-reactid="1612" href="/utopian-io/@scipio/scipio-s-utopian-intro-post-the-scipio-files-14"><!-- react-text: 1613 -->Scipio's Utopian Intro Post - The Scipio Files #14<!-- /react-text --></a>, <a data-reactid="1691" href="/utopian-io/@scipio/gsaw-js-v0-3-more-powerful-still-just-as-easy-configuration-options-and-virtual-stylesheet-injection-the-scipio-files-13"><!-- react-text: 1692 -->gsaw-JS v0.3 - More powerful, still just as easy: Configuration Options & Virtual Stylesheet Injection! - The Scipio Files #13<!-- /react-text --></a>, <a data-reactid="1775" href="/utopian-io/@steem-plus/steemplus-v2-easier-safer"><!-- react-text: 1776 -->SteemPlus v2: Easier, Safer<!-- /react-text --></a>]
Using the attrs attribute
It worked, a list of anchors is returned, but the data still looks "messy" (mostly because of all the reactJS tags inside all <a> tags), so let's clean it up using the bs4 attrs attribute.
If you look at the first element inside the returned list, the part we're interested in is the (relative) url contained in the href="" HTML attribute, in this case: href="/utopian-io/@scipio/learn-python-series-12-handling-files". Because that's the same data structure for every anchor in the list, let's loop over each element in the list and distill the relative urls, like this:
anchors = soup.select('h2.articles__h2 a')
for a in anchors:
href = a.attrs['href']
print(href)
print(len(anchors))
/utopian-io/@scipio/learn-python-series-12-handling-files
/utopian-io/@scipio/learn-python-series-11-numpy-part-1
/utopian-io/@scipio/learn-python-series-10-matplotlib-part-1
/utopian-io/@scipio/learn-python-series-9-using-import
/utopian-io/@scipio/learn-python-series-8-handling-tuples
/utopian-io/@scipio/learn-python-series-7-handling-dictionaries
/utopian-io/@scipio/learn-python-series-6-handling-lists-part-2
/utopian-io/@scipio/learn-python-series-5-handling-lists-part-1
/utopian-io/@scipio/learn-python-series-4-round-up-1
/utopian-io/@scipio/learn-python-series-3-handling-strings-part-2
/utopian-io/@scipio/learn-python-series-2-handling-strings-part-1
/utopian-io/@scipio/learn-python-series-intro
/steemit/@scipio/it-s-my-birthday-on-steemit-100-days
/steemdev/@scipio/i-m-still-here-ua-python-is-coming
/introduce-yourself/@femdev/let-s-introduce-myself-femdev
/utopian-io/@howo/introducing-steempress-beta-a-wordpress-plugin-for-steem
/pixelart/@fabiyamada/a-little-present-for-scip-sensei-the-scipio-files-pixelart
/utopian-io/@scipio/scipio-s-utopian-intro-post-the-scipio-files-14
/utopian-io/@scipio/gsaw-js-v0-3-more-powerful-still-just-as-easy-configuration-options-and-virtual-stylesheet-injection-the-scipio-files-13
/utopian-io/@steem-plus/steemplus-v2-easier-safer
20
That's much better! I also printed the size of the anchors list, it prints 20 meaning the latest 20 article posts are contained in the list. (Again, I've published more, but those only get loaded and rendered in the browser when you scroll to the bottom of the page, and therefore apparently not all my article posts are contained in the initial pageload).
However, these are all rrelative urls: in order to use them, we need to prepend via concatenation the https:// scheme and domain name steemit.com in front of them to convert them into absolute urls:
anchors = soup.select('h2.articles__h2 a')
for a in anchors:
href = 'https://steemit.com' + a.attrs['href']
print(href)
https://steemit.com/utopian-io/@scipio/learn-python-series-12-handling-files
https://steemit.com/utopian-io/@scipio/learn-python-series-11-numpy-part-1
https://steemit.com/utopian-io/@scipio/learn-python-series-10-matplotlib-part-1
https://steemit.com/utopian-io/@scipio/learn-python-series-9-using-import
https://steemit.com/utopian-io/@scipio/learn-python-series-8-handling-tuples
https://steemit.com/utopian-io/@scipio/learn-python-series-7-handling-dictionaries
https://steemit.com/utopian-io/@scipio/learn-python-series-6-handling-lists-part-2
https://steemit.com/utopian-io/@scipio/learn-python-series-5-handling-lists-part-1
https://steemit.com/utopian-io/@scipio/learn-python-series-4-round-up-1
https://steemit.com/utopian-io/@scipio/learn-python-series-3-handling-strings-part-2
https://steemit.com/utopian-io/@scipio/learn-python-series-2-handling-strings-part-1
https://steemit.com/utopian-io/@scipio/learn-python-series-intro
https://steemit.com/steemit/@scipio/it-s-my-birthday-on-steemit-100-days
https://steemit.com/steemdev/@scipio/i-m-still-here-ua-python-is-coming
https://steemit.com/introduce-yourself/@femdev/let-s-introduce-myself-femdev
https://steemit.com/utopian-io/@howo/introducing-steempress-beta-a-wordpress-plugin-for-steem
https://steemit.com/pixelart/@fabiyamada/a-little-present-for-scip-sensei-the-scipio-files-pixelart
https://steemit.com/utopian-io/@scipio/scipio-s-utopian-intro-post-the-scipio-files-14
https://steemit.com/utopian-io/@scipio/gsaw-js-v0-3-more-powerful-still-just-as-easy-configuration-options-and-virtual-stylesheet-injection-the-scipio-files-13
https://steemit.com/utopian-io/@steem-plus/steemplus-v2-easier-safer
Wrapping it all up into a function
In order to re-use the code we just ran, we need to wrap the code inside a function and instead of printing each article url the function should return one list containing all absolute urls. Like this:
# import requests and bs4
import requests
from bs4 import BeautifulSoup
# function definition, user parameter for flexibility
def get_latest_articles(user):
# create an empty article list
article_list = []
# fetch account page html using requests
url = 'https://steemit.com/@' + user
r = requests.get(url)
content = r.text
# fetch article urls using bs4
soup = BeautifulSoup(content, 'lxml')
anchors = soup.select('h2.articles__h2 a')
# iterate over all tags found
for a in anchors:
# distill the url, modify to absolute
href = 'https://steemit.com' + a.attrs['href']
# append the url to the article_list
article_list.append(href)
return article_list
# call the function, let's now get the latest posts from
# Steemit user @zoef
latest_articles = get_latest_articles('zoef')
print(latest_articles)
['https://steemit.com/utopian-io/@zoef/the-utopian-contributor-assign', 'https://steemit.com/utopian-io/@zoef/feroniobot-logo-contribution', 'https://steemit.com/utopian-io/@zoef/steem-casino-logo-contribution', 'https://steemit.com/religion/@zoef/religion-vs-believer', 'https://steemit.com/utopian-io/@zoef/flashlight-logo-proposal', 'https://steemit.com/blocktrades/@zoef/stopping-my-15k-delegation', 'https://steemit.com/blog/@zoef/center-parcs-2', 'https://steemit.com/alldutch/@zoef/center-parcs-erperheide', 'https://steemit.com/religion/@zoef/i-a-man-atheist', 'https://steemit.com/utopian-io/@zoef/steem-assistant-logo-contribution', 'https://steemit.com/anime/@zoef/anime-s-i-currently-watch', 'https://steemit.com/alldutch/@zoef/stargate-origins-first-glance', 'https://steemit.com/alldutch/@zoef/logo-remake-for-fotografie-sandy-2', 'https://steemit.com/alldutch/@zoef/logo-remake-for-fotografie-sandy', 'https://steemit.com/graphic/@zoef/utopian-logo-contribution-template', 'https://steemit.com/zappl/@zoef/first-time-zappling-d', 'https://steemit.com/blog/@zoef/exam-analysis', 'https://steemit.com/blog/@zoef/the-judgment-of-utopian-mods-part-3', 'https://steemit.com/blog/@zoef/conan-exiles-survival-game-from-funcom', 'https://steemit.com/blog/@zoef/the-judgment-of-utopian-mods-part-2']
What did we learn, hopefully?
We've discussed a lot in this episode! We installed and imported the Requests and BeautifulSoup4 libraries, so we can fetch and parse web page data. We also had a brief look (again) about how HTML and CSS work, so we could use that knowledge to select specific HTML elements with the bs4 select() method. We also learned that - in order to develop a custom web crawler - we need a plan. And we need insights where to look inside the code structure and think of a decent "strategy" to fetch exactly the data we're looking for, fully automatically. We used just a tiny bit of string manipulation to convert the relative Steemit article urls to absolute urls, and finally we coded a re-usable function get_latest_articles() to get the latest post from any Steem user.
This was a lot of fun (at least I had fun writing this!) but we can do much-much-much more with crawling the web and using the data we gathered. Let's see what we can code in the next episode!
Thank you for your time!
Posted on Utopian.io - Rewarding Open Source Contributors